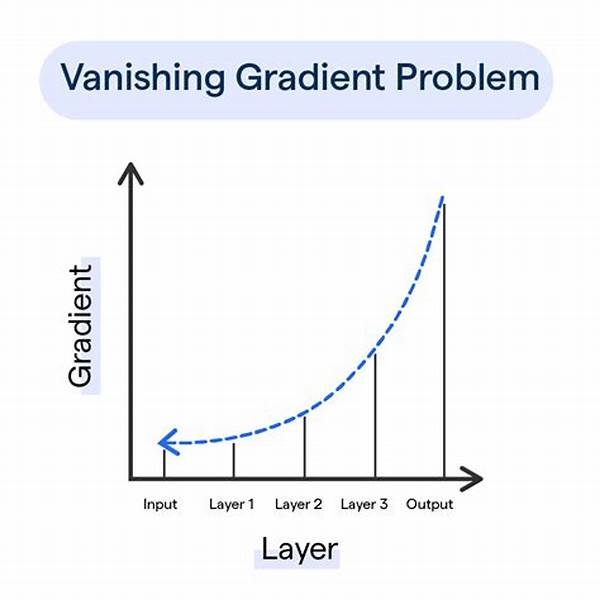
In the ever-evolving landscape of neural networks, the vanishing gradient problem has represented a significant challenge. Historically, it has constrained the training of deep neural networks, limiting their capacity to generalize and perform effectively. The vanishing gradient problem occurs when gradients become exceedingly small, effectively stalling the learning process. This phenomenon primarily affects networks with many layers, rendering them incapable of updating weights effectively. As machine learning researchers sought to deepen networks for improved performance, addressing the vanishing gradient problem became imperative. Consequently, various vanishing gradient problem solutions have emerged, revolutionizing the field by enabling the development of efficient, deep architectures. This discourse delves into these vanishing gradient problem solutions, elucidating their principles and applications.
Read Now : “simplifying Complex Visual Data”
Exploring Solutions to the Vanishing Gradient Problem
Neural networks constitute the backbone of modern machine learning applications. However, the vanishing gradient problem long posed a formidable challenge to the advancement of these technologies. The vanishing gradient problem primarily affects deep networks during backpropagation, where gradients computed in earlier layers tend to shrink towards zero as they propagate backward. This attenuation results in negligible updates to network weights, severely impeding learning and convergence. Consequently, the quest for vanishing gradient problem solutions gained traction, prompting researchers to devise methodologies to counteract this impediment.
Innovative vanishing gradient problem solutions have burgeoned, starting with the introduction of activation functions like ReLU (Rectified Linear Unit). Unlike traditional sigmoid or tanh functions with their derivative bottlenecks, ReLU maintains gradient magnitude consistent across layers. Furthermore, architectural advances like Residual Networks (ResNets) introduce shortcut connections that facilitate gradient flow, effectively addressing the problem in deeper networks. Another class of vanishing gradient problem solutions involves normalization techniques, such as Batch Normalization, which standardize inputs to network layers, preserving gradient magnitudes. Each of these advancements has contributed significantly to mitigating the adverse effects of the vanishing gradient problem, enabling the realization of more robust and efficient neural architectures.
Strategies for Addressing the Vanishing Gradient Problem
1. ReLU Activation Functions: ReLU addresses the vanishing gradient problem by maintaining a consistent gradient magnitude. Unlike sigmoid or tanh, ReLU does not suffer from exponential decay, maintaining effective weight updates even in deep layers.
2. Residual Networks (ResNets): ResNets mitigate the vanishing gradient problem by integrating shortcut connections that bypass multiple layers, facilitating seamless gradient flow in deep networks.
3. Batch Normalization: This technique standardizes inputs, preserving gradient sizes and improving the learning speed and stability of networks, addressing vanishing gradient challenges.
4. Weight Initialization: Smart initialization strategies, such as Xavier or He initialization, improve gradient propagation by maintaining balanced activations and gradients throughout the network, mitigating the vanishing gradient issue.
5. Gradient Clipping: By setting maximum threshold values for gradients, gradient clipping prevents vanishing, ensuring effective learning even in challenging deep networks by preserving effective gradient sizes.
Advanced Techniques in Vanishing Gradient Problem Solutions
The mathematical intricacies of deep neural networks often lead to the vanishing gradient problem, confounding efforts to enhance learning and convergence. Over the years, various vanishing gradient problem solutions have emerged as researchers engineered architectures and methodologies to facilitate effective gradient flow. Among these methodologies is the employment of activation functions tailored to promote stability and efficiency in training.
ReLU stands as a pivotal component of vanishing gradient problem solutions by offering a linear path for positive input values, thereby circumventing the zero-derivative bottleneck associated with traditional functions. Another significant breakthrough is the inception of Residual Networks (ResNets), which incorporate residual learning frameworks. By constructing identity mappings, ResNets enable gradients to traverse unrestrictedly across layers, greatly enhancing the trainability of deep networks. Furthermore, vanishing gradient problem solutions extend to normalization techniques, such as Batch Normalization, which corrects for covariance shifts and ensures consistent gradient scales. Together, these methodologies collectively empower neural networks to transcend the vanishing gradient limitations, unlocking potentials for deeper architectures and more sophisticated applications.
Implementing Vanishing Gradient Problem Solutions in Practice
Implementing vanishing gradient problem solutions has been pivotal in empowering modern neural network models. These solutions have been incorporated through a series of methodologies, each addressing specific facets of the vanishing gradient challenge. In practice, activation functions like ReLU have proven instrumental by allowing continuous gradients, thus overcoming earlier derivative issues associated with sigmoid functions.
Read Now : “market-based Climate Adaptation Solutions”
Advanced architectures, notably Residual Networks, have redefined the landscape of deep learning models. By introducing alternate pathways for gradient flow, ResNets have effectively circumvented the limitations imposed by the vanishing gradient problem. Weight initialization strategies such as Xavier initialization have also been pivotal in ensuring that gradients remain robust from the outset, promoting efficient learning across layers. Furthermore, batch normalization techniques maintain consistent gradient sizes by adjusting and scaling inputs, contributing significantly to addressing the vanishing gradient problem. These vanishing gradient problem solutions have collectively revolutionized the capability and depth of neural network models, facilitating their widespread application across diverse fields.
Critical Insights into Vanishing Gradient Problem Solutions
The persistent challenge of the vanishing gradient problem necessitates a sophisticated approach to neural network design. At the core of addressing this issue lies an understanding of the mathematical underpinnings that give rise to vanishing gradients. This understanding has been pivotal in developing innovative vanishing gradient problem solutions, enabling network architectures to evolve into more complex and efficient forms.
The integration of activation functions, specifically ReLU, represents a foundational element in vanishing gradient problem solutions. With its propensity to maintain effective gradients, ReLU alleviates the zero-derivative predicament of logistic functions. Moreover, deep networks have benefited significantly from the emergence of Residual Networks, which employ identity mappings to facilitate gradient flow across layers. These networks are bolstered by advances in weight initialization, with Xavier and He initialization methods ensuring balanced activations throughout the architecture. Finally, normalization techniques have served to stabilize network inputs, preserving gradient magnitudes and ensuring efficient convergence. Together, these vanishing gradient problem solutions have comprehensively addressed the challenges posed by vanishing gradients, strengthening the reliability and effectiveness of deep learning systems.
Evaluating the Efficacy of Vanishing Gradient Problem Solutions
With the advent of deep learning, the compulsion to resolve the vanishing gradient problem became critical for effective model training. The various vanishing gradient problem solutions implemented have significantly transformed neural network architectures. One noteworthy development is the intricate design of Rectified Linear Units (ReLU) as a superior activation function. Its unique properties bypass the constraining gradient decrease associated with logistic activations.
Furthermore, the innovation of Residual Networks marked a pivotal progression in addressing the vanishing gradient problem. Through innovative shortcut pathways, ResNets enable gradients to flow unimpeded, preserving effective learning across extensive layers. Significantly, advanced initialization strategies, such as Xavier or He initialization, address gradient propagation issues head-on, ensuring a balanced distribution of activation functions from initial layers onward. Such innovations represent crucial strides in mitigating the vanishing gradient problem. Additionally, techniques such as Batch Normalization play a vital role by standardizing network inputs, thereby maintaining effective gradient levels. Collectively, these approaches have cemented their place in modern deep learning, providing robust vanishing gradient problem solutions that advance neural network capabilities.
Conclusion on Vanishing Gradient Problem Solutions
Within the sphere of deep learning, the vanishing gradient problem posed a serious impediment to the growth and performance of neural networks. However, the emergence of diverse vanishing gradient problem solutions has precipitated a profound shift in this paradigm. Contributions ranging from novel activation functions to architectural innovations like Residual Networks have redefined neural paradigms. With the establishment of ReLU, network layers now maintain continuity of gradient flow, overcoming limitations posed by earlier methodologies.
Another crucial dimension in vanishing gradient problem solutions lies in network design strategies, which have incorporated shortcut connections and improved initialization techniques. These strategies facilitate effective learning even in extensive networks by ensuring gradients remain viable across all layers. By mitigating the effects of vanishing gradients, approaches such as Batch Normalization further enhance learning efficiency. Collectively, these solutions offer a comprehensive framework for addressing the vanishing gradient problem, enabling the creation of more efficient, deeper, and reliable networks. The continuous evolution of these methods represents a beacon of progress in the ongoing quest to optimize deep learning systems and harness their full potential.