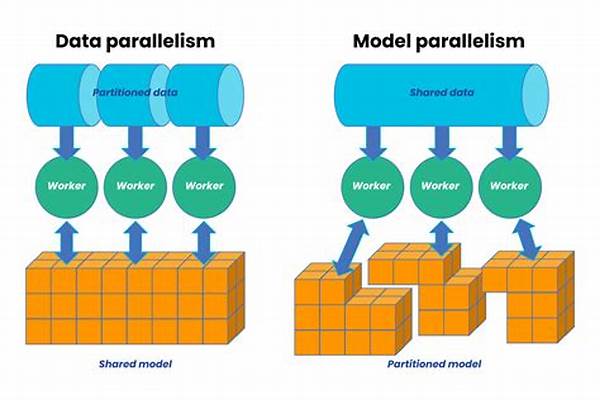
As the volume of data rapidly expands in the digital age, the necessity for efficient data processing methods has become paramount. Parallel computing frameworks for big data are critical in managing and analyzing massive datasets effectively. These frameworks enable the simultaneous processing of data across multiple computing nodes, thereby significantly enhancing computational speed and efficiency. The significance of these frameworks is underscored by their ability to handle large-scale data processing tasks that are beyond the capacity of traditional serial computing methods.
Read Now : Rest Api Data Serialization Formats
The Role of Parallel Computing Frameworks
Parallel computing frameworks for big data play a crucial role in the modern data-driven landscape. Designed to manage massive amounts of data, these frameworks streamline data processing by splitting large tasks into smaller, manageable sub-tasks. This division of labor allows for concurrent execution across multiple processors, which not only accelerates computational processes but also enhances the overall efficiency and scalability of data operations. By leveraging parallel computing frameworks, organizations can perform complex data analytics in real-time, reducing latency and increasing throughput. Moreover, these frameworks are essential for executing machine learning algorithms on colossal datasets, enabling faster model training and more accurate predictive insights. Through their adept handling of resource-intensive tasks, parallel computing frameworks empower businesses to derive valuable insights more swiftly, ultimately fostering innovation and informed decision-making.
Key Features of Parallel Computing Frameworks
1. Scalability: Parallel computing frameworks for big data are designed to scale seamlessly with growing data volumes. They accommodate increases in data load by distributing tasks efficiently across computing resources, ensuring consistent performance.
2. Fault Tolerance: These frameworks include robust fault-tolerance mechanisms that maintain operation integrity even in the event of hardware or software failures, thereby ensuring data consistency and reliability.
3. Efficiency: By breaking down large processing tasks into smaller sub-tasks that run concurrently, parallel computing frameworks optimize resource utilization and reduce processing time significantly.
4. Flexibility: These frameworks support a variety of data processing patterns and programming models, allowing customization to suit diverse processing needs and application domains.
5. Cost-Effectiveness: By maximizing existing hardware resources and minimizing the need for expensive infrastructure upgrades, parallel computing frameworks provide an economically viable solution for large-scale data processing.
Challenges and Considerations
While parallel computing frameworks for big data present numerous benefits, they also come with a set of challenges and considerations. One primary challenge is the complexity involved in developing parallel algorithms and the requisite programming skills needed to implement them effectively. Furthermore, data synchronization and coordination among multiple nodes can introduce additional overhead, potentially affecting performance if not managed properly. Another consideration is the cost of maintaining infrastructure capable of supporting distributed processing environments, which may require investment in high-performance computing resources. Additionally, while fault tolerance is a strength of these frameworks, ensuring seamless recovery from failures without data loss or corruption requires meticulous system configuration and management. It is imperative for organizations to weigh these factors and consider both the technical and financial aspects when adopting parallel computing solutions for their big data needs.
Implementation Strategies
1. Understanding Data Characteristics: Before adopting parallel computing frameworks for big data, it is critical to understand the specific characteristics of the data, including volume, velocity, and variety, to tailor the framework configuration accordingly.
2. Choosing the Right Tools: Selecting the most suitable parallel computing framework involves assessing available tools like Apache Hadoop, Apache Spark, and others, based on their compatibility with organizational goals and existing infrastructures.
Read Now : Voice-enabled Collaboration Tools
3. Resource Allocation: Efficient resource allocation is vital to optimize the performance of parallel computing frameworks. Dynamic load balancing can further enhance resource utilization across distributed nodes.
4. Continuous Monitoring: Establish robust monitoring systems to track the performance of parallel computing frameworks, enabling timely identification and resolution of bottlenecks or failures.
5. Security Measures: Implement security protocols to safeguard data integrity and confidentiality within distributed environments, a critical aspect when handling sensitive data.
Future Directions in Parallel Computing Frameworks
The future of parallel computing frameworks for big data holds promising avenues for advancement. With the continued growth of data and the increasing demand for accelerated processing times, these frameworks are evolving to integrate cutting-edge technologies such as artificial intelligence and machine learning. Future iterations of parallel computing frameworks are expected to offer autonomous features, enabling self-optimization and self-repair capabilities to further enhance reliability and performance. Moreover, advances in quantum computing may redefine the paradigms of parallel data processing, offering unprecedented computational power for tackling the most complex data challenges. As organizations aim to harness the full potential of big data, investing in next-generation parallel computing frameworks will be pivotal to maintaining a competitive edge in the ever-evolving digital landscape.
Conclusion
Parallel computing frameworks for big data stand as fundamental components in the contemporary data processing ecosystem. They provide essential capabilities to handle vast and complex data sets efficiently, offering scalability, speed, and reliability. As data continues to proliferate, the importance of these frameworks becomes even more pronounced, facilitating advanced analytics and decision-making processes across various sectors. By addressing the challenges associated with large-scale data processing, organizations can unlock significant opportunities for innovation, efficiency, and growth. Consequently, the strategic implementation of parallel computing frameworks remains a critical endeavor for enterprises seeking to stay at the forefront of the data revolution.
Summary
Parallel computing frameworks for big data have emerged as indispensable tools in managing the complex and voluminous data characteristic of today’s digital era. These frameworks boost data processing capabilities by leveraging the power of concurrent operations across distributed computing resources. With their inherent scalability and fault-tolerance features, they ensure robust performance even as data volumes continue to escalate. Employing parallel computing frameworks allows organizations to execute intricate data analyses and machine learning processes swiftly, enabling real-time insights and enhanced decision-making. Crucially, the adoption of these frameworks necessitates strategic planning and resource allocation to mitigate the challenges of parallel algorithm design and infrastructure management. As technological advancements progress, the evolution of parallel computing frameworks will continue to expand their capabilities, providing organizations with potent tools to manage, analyze, and derive actionable insights from big data.