The burgeoning domain of big data has brought forth numerous challenges and opportunities for businesses and organizations. One critical aspect in managing big data effectively is the implementation of ETL (Extract, Transform, Load) processes. ETL processes for big data are pivotal in ensuring that the data, arriving from numerous sources, is systematically organized and made readily available for analysis. This article delves into various facets of ETL processes, emphasizing their significance, methodologies, and considerations in the realm of big data.
Read Now : Scaling Continuous Deployment In Microservices
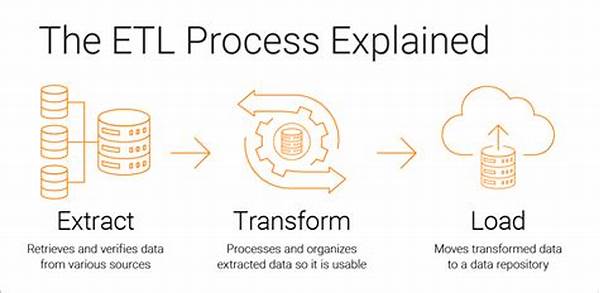
Understanding ETL Processes in Big Data
ETL processes for big data serve as the backbone of data management within large-scale environments. Initially, data extraction involves retrieving a plethora of data from disparate sources, often in various formats ranging from structured to unstructured data. Subsequently, this data undergoes transformation, where it is cleaned, enriched, and standardized to ensure uniformity and quality. Finally, the processed data is loaded into a designated data repository, preparing it for further analysis. Given the sheer volume, velocity, and variety inherent in big data, ETL processes must be robust, scalable, and flexible to handle such complexities effectively. These processes lay the foundational framework that enables organizations to derive insightful analytics and make informed decisions.
Key Components of ETL Processes for Big Data
1. Data Extraction: This phase involves gathering raw data from multiple sources. It includes handling various data formats prevalent in big data environments.
2. Data Transformation: Once extracted, data must be formatted. This phase ensures data quality and relevance by cleansing, aggregating, and modifying the data.
3. Data Loading: The final phase involves placing data into a target database or data warehouse, making it accessible for analytics purposes.
4. Scalability: ETL processes for big data require architectures that can expand to accommodate increasing data volumes without compromising performance or reliability.
5. Real-Time Processing: Integrating real-time data processing capabilities in ETL allows for immediate insights, vital for time-sensitive decision-making.
Challenges in ETL Processes for Big Data
The successful implementation of ETL processes for big data requires addressing several challenges. These include managing the sheer volume of data, which necessitates scalable and robust infrastructures. Additionally, the velocity of data streaming in real-time situations demands immediate processing capabilities that traditional ETL processes may not support. Another challenge lies in the variety of data, requiring sophisticated transformation techniques to handle unstructured data, such as text, images, or video. Implementing effective data governance and ensuring data quality across diverse datasets further adds complexity to these processes. Consequently, organizations must adopt innovative technologies and strategies to mitigate these challenges, ensuring seamless ETL operations that support big data analytics and decision-making.
Best Practices for ETL Processes in Big Data
1. Automate Data Validation: Automation in ETL processes for big data ensures consistency and reduces manual intervention, enhancing efficiency and accuracy.
2. Invest in Scalable Technologies: Using scalable technologies caters to growing data volumes, thus avoiding bottlenecks in the ETL pipeline.
3. Opt for Cloud-Based Solutions: Cloud solutions provide agility and scalability, aligning with modern ETL requirements for big data.
4. Implement Data Encryption: Data security is paramount; therefore, incorporating encryption during ETL processes helps protect sensitive data.
5. Leverage Parallel Processing: Utilizing parallel processing frameworks can boost the speed and performance of ETL tasks, adapting to big data’s demands.
6. Ensure Data Quality: Always prioritize robust data quality mechanisms to maintain reliable analytics outcomes post-ETL.
Read Now : Implementing Microservices With Docker
7. Perform Regular Monitoring: Continuous monitoring of ETL processes helps in promptly identifying and rectifying anomalies, maintaining process integrity.
8. Adopt Real-Time ETL: Real-time capabilities in ETL processes for big data facilitate swift data flow and immediate insights, vital for dynamic business environments.
9. Harness Machine Learning: Implementing machine learning can enhance the transformation stage, particularly in handling large and complex datasets.
10. Prioritize Data Governance: Strong data governance frameworks ensure compliance and efficiencies across ETL processes, especially crucial for compliance and strategic alignment.
Implementing Effective ETL in Big Data Environments
Implementing ETL processes for big data is a multi-faceted endeavor requiring meticulous planning and execution. Selecting the right tools and technologies is pivotal to achieving seamless ETL operations. Among these, organizations should prioritize tools capable of handling vast data volumes and providing real-time processing capabilities to cater to immediate analytical needs. Furthermore, it is imperative to establish a cohesive framework that supports data consistency and quality across various data models, leveraging automated data validation and cleansing techniques to ensure reliability.
Equally significant is the role of a skilled team well-versed in modern ETL methodologies. Professionals must be equipped with the knowledge to implement scalable and adaptable solutions, ensuring that the ETL processes align with the dynamic nature of big data environments. Continuous training and skill enhancement are essential to keeping abreast of evolving technologies and best practices. Moreover, fostering collaboration between IT and business units can lead to more effective ETL strategies tailored to the specific needs of an organization, ensuring that data insights are timely and practically applicable.
Advanced ETL Strategies for Big Data
In an ever-evolving digital landscape, advanced ETL strategies are indispensable for thriving in big data environments. Organizations need to embrace not only traditional ETL processes but also innovative techniques like stream processing for real-time data. This shift involves migrating from rigid batch processing to more fluid and dynamic ETL methodologies that can seamlessly handle data influxes, ensuring timely information processing and delivery to data consumers.
Advanced ETL processes for big data also require integrating machine learning models that enhance data transformation and analysis stages. These models can automatically detect patterns, anomalies, and trends within datasets, elevating the overall analytical capabilities post-ETL. Furthermore, leveraging distributed computing frameworks such as Hadoop and Spark helps manage processing loads efficiently, enabling high-speed data manipulation and reducing latency, ultimately leading to faster insights and robust decision-making frameworks.
Conclusion on ETL Processes for Big Data
In summary, the implementation of ETL processes for big data is crucial in the utilization of voluminous information in today’s data-driven world. These processes enable organizations to convert raw data into actionable insights, fostering informed decision-making and strategic interventions. A well-prepared ETL ecosystem supported by scalable technologies, real-time processing capabilities, and skilled personnel underpins the effectiveness of such initiatives.
By addressing the complexities inherent in big data, ETL processes facilitate a seamless transition from data extraction to loading, a journey marked by meticulous transformation. This endeavor demands continuous innovation and adaptation to cater to ever-growing data demands. Consequently, organizations are urged to engage in constant evaluation and enhancement of their ETL strategies, ensuring resilience and effectiveness in their operations, ultimately driving competitive advantage and sustained growth in an increasingly competitive landscape.