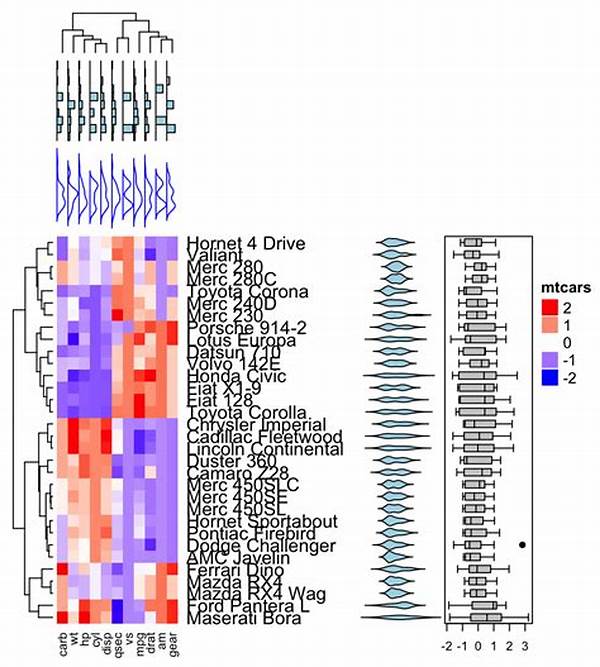
In the field of machine learning, unsupervised learning cluster analysis serves as a pivotal tool for data analysis, offering insights without the need for labeled data. Distinguished from its supervised counterpart, unsupervised learning delves into the intrinsic structure of a dataset, identifying patterns and grouping data into clusters based on their characteristics. This type of analysis is invaluable in various domains, including market segmentation, social network analysis, and anomaly detection.
Read Now : Cloud Service Provider Encryption Policies
The Fundamentals of Unsupervised Learning Cluster Analysis
Unsupervised learning cluster analysis operates by partitioning a dataset into subsets or clusters, wherein each cluster comprises data points with similar attributes. The essence of this analysis is to unveil hidden patterns and structures within the data, facilitating a deeper understanding of the dataset at hand. With applications spanning across numerous fields, from image and speech recognition to bioinformatics, unsupervised learning cluster analysis stands at the forefront of technological advancement.
In practical scenarios, techniques such as k-means, hierarchical clustering, and DBSCAN are often employed to execute unsupervised learning cluster analysis. These methods, each with its unique approach, aid in grouping data points, enabling researchers and analysts to decipher complex datasets without predefined labels or categories. The flexibility and adaptability of unsupervised learning cluster analysis make it a critical component in the toolkit of data scientists and analysts worldwide.
Key Characteristics of Unsupervised Learning Cluster Analysis
1. Data Independence: Unsupervised learning cluster analysis does not require labeled data, distinguishing it from supervised learning methods.
2. Pattern Identification: It excels in identifying hidden patterns and structures within a dataset.
3. Versatile Applications: This analysis method is applicable across diverse sectors, including finance, healthcare, and marketing.
4. Algorithm Variety: Various algorithms such as k-means and DBSCAN are utilized, each suited to different types of data.
5. Scalability: It is highly scalable, capable of handling large datasets efficiently.
Techniques in Unsupervised Learning Cluster Analysis
Focusing on the methods employed, unsupervised learning cluster analysis incorporates a variety of techniques tailored to different data structures and application requirements. One prominent technique is the k-means clustering algorithm, which partitions data into k distinct clusters, where each data point belongs to the cluster with the nearest mean. This method is efficient and widely used due to its simplicity and applicability to large datasets.
Another significant method within unsupervised learning cluster analysis is hierarchical clustering, which builds a tree of clusters. Unlike k-means, hierarchical clustering does not require the number of clusters to be specified beforehand, thus offering more flexibility. It merges or divides clusters based on distance criteria, forming a dendrogram that represents the nested arrangement of data points in a hierarchical structure.
Read Now : Api Security In Digital Transformation
Applications of Unsupervised Learning Cluster Analysis
Unsupervised learning cluster analysis finds its utility across various domains, adapting to the needs of different sectors. In marketing, it is instrumental in customer segmentation, enabling businesses to personalize their offerings and strategies. In the field of biology, it assists in gene expression analysis, grouping genes with similar expression patterns. In security, unsupervised learning cluster analysis can detect anomalies, identifying irregular patterns that may indicate fraudulent activities or cyber threats.
The insights derived from unsupervised learning cluster analysis inform decision-making, enhance operational efficiency, and contribute to the advancement of scientific research. By uncovering the natural structure of data, it facilitates a deeper comprehension, driving innovation and development across multiple industries.
Challenges and Future Directions in Unsupervised Learning Cluster Analysis
Despite its numerous advantages, unsupervised learning cluster analysis faces challenges related to the interpretation and evaluation of results. The absence of predefined labels makes it difficult to assess the accuracy of the clustering outcomes, necessitating the development of robust evaluation metrics. Moreover, the selection of an appropriate clustering algorithm and the determination of optimal parameter values remain critical tasks requiring expert judgment.
Looking ahead, advancements in computational power and algorithmic design will likely enhance the effectiveness and efficiency of unsupervised learning cluster analysis. The integration of auxiliary techniques, such as dimensionality reduction and deep learning, may address existing limitations, paving the way for the discovery of increasingly complex patterns and relationships within data. Continued research and innovation in this domain are essential to fully exploit the potential of unsupervised learning cluster analysis in solving real-world problems.
Evaluating the Effectiveness of Unsupervised Learning Cluster Analysis
Evaluating the efficacy of unsupervised learning cluster analysis is paramount in ensuring the reliability of the results obtained. One common approach involves the use of internal evaluation metrics, such as the silhouette score, which assesses the compactness and separation of clusters. Furthermore, visual inspection of clustering results through dimensionality reduction techniques like PCA or t-SNE can provide an intuitive understanding of the data distribution.
As unsupervised learning cluster analysis continues to evolve, the development of sophisticated evaluation methods will play a crucial role in enhancing its applicability and trustworthiness. By addressing methodological challenges, researchers can unlock new frontiers in data analysis, fueling progress across myriad fields. Embracing these advancements will empower organizations to harness the full potential of their data, driving growth and success in an increasingly data-driven world.